
Dalam dunia manipulasi dan analisis teks, kemampuan untuk mencari dan mencocokkan substring (bagian dari string) secara efisien adalah keterampilan yang sangat berharga. Salah satu alat yang ampuh untuk tugas ini adalah regular expression (regexp) POSIX. Regexp POSIX menyediakan sintaks standar untuk mendefinisikan pola pencarian yang kompleks, memungkinkan kita untuk mengidentifikasi, mengekstrak, dan memvalidasi substring dengan presisi tinggi. Artikel ini akan membahas secara mendalam tentang bagaimana menggunakan operator regexp POSIX untuk pencocokan substring, mencakup sintaks dasar, operator lanjutan, contoh penggunaan praktis, dan pertimbangan kinerja.
H2. Dasar-Dasar Regexp POSIX untuk Pencocokan Substring
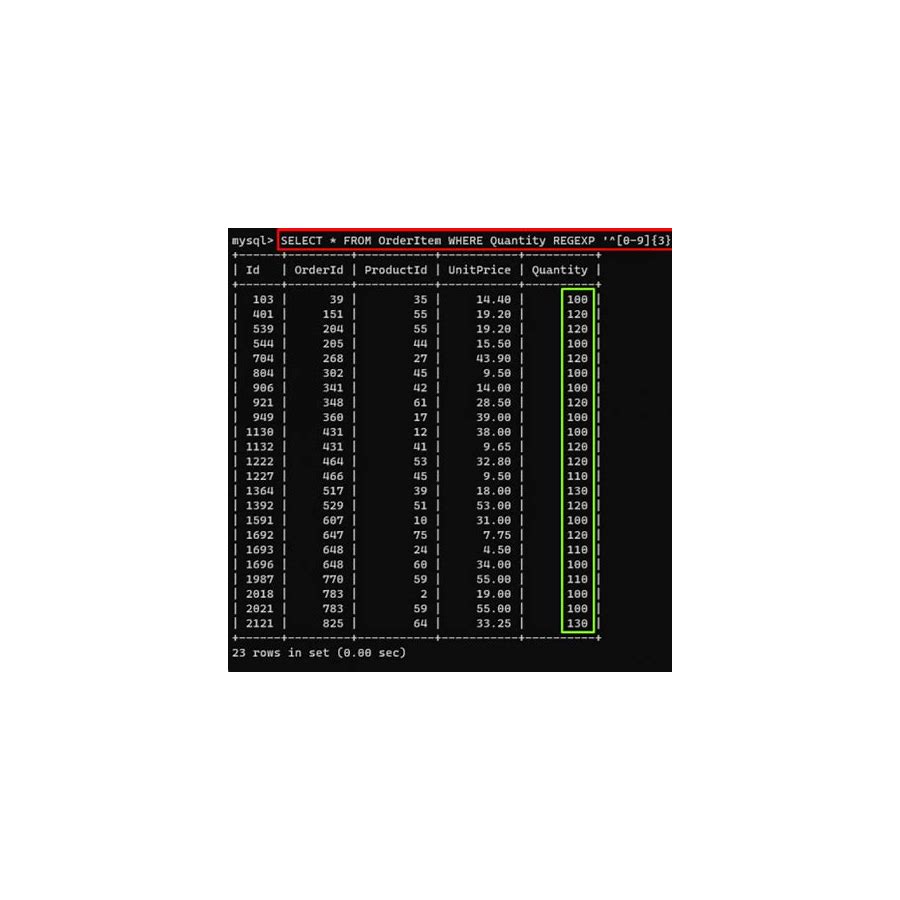
Regular expression (regexp) adalah urutan karakter yang mendefinisikan pola pencarian. POSIX (Portable Operating System Interface) adalah standar yang mendefinisikan sintaks dan perilaku regexp, memastikan konsistensi di berbagai platform dan bahasa pemrograman. Dalam konteks pencocokan substring, regexp POSIX memungkinkan kita untuk mencari pola tertentu di dalam string yang lebih besar.
Sintaks Dasar:
.(titik): Mencocokkan karakter apa pun kecuali baris baru.^(caret): Mencocokkan awal string.$(dollar): Mencocokkan akhir string.*(asterisk): Mencocokkan nol atau lebih kemunculan karakter atau grup sebelumnya.+(plus): Mencocokkan satu atau lebih kemunculan karakter atau grup sebelumnya.?(tanda tanya): Mencocokkan nol atau satu kemunculan karakter atau grup sebelumnya.[](kurung siku): Mendefinisikan set karakter. Misalnya,[abc]cocok dengan 'a', 'b', atau 'c'.[^](kurung siku dengan caret): Mendefinisikan set karakter yang dikecualikan. Misalnya,[^abc]cocok dengan karakter apa pun kecuali 'a', 'b', atau 'c'.\(backslash): Melarikan diri karakter khusus. Misalnya,\.cocok dengan karakter titik literal.()(kurung): Mengelompokkan ekspresi untuk aplikasi operator atau untuk menangkap substring yang cocok.|(pipa): Menunjukkan alternatif. Misalnya,a|bcocok dengan 'a' atau 'b'.
Contoh Sederhana:
abc: Mencocokkan string "abc" secara literal.a.c: Mencocokkan string yang dimulai dengan 'a', diikuti oleh karakter apa pun, dan diakhiri dengan 'c'. Contoh: "abc", "a1c", "a c".[0-9]+: Mencocokkan satu atau lebih digit. Contoh: "1", "123", "007".^hello: Mencocokkan string yang dimulai dengan "hello".world$: Mencocokkan string yang diakhiri dengan "world".
Implementasi dalam Bahasa Pemrograman:
Banyak bahasa pemrograman mendukung regexp POSIX melalui library atau modul bawaan. Contohnya:
- Python: Modul
remenyediakan fungsi untuk bekerja dengan regexp. - JavaScript: Objek
RegExpmenyediakan metode untuk pencocokan string. - PHP: Fungsi
preg_match,preg_replace, dll. mendukung regexp. - Java: Kelas
java.util.regex.Patterndanjava.util.regex.Matchermenyediakan fungsionalitas regexp.
Contoh Python:
import re string = "Ini adalah contoh string dengan angka 123." pola = r"[0-9]+" # Pola untuk mencocokkan satu atau lebih digit cocok = re.search(pola, string) if cocok: print("Substring yang cocok:", cocok.group(0)) # Output: Substring yang cocok: 123 else: print("Tidak ada kecocokan ditemukan.") H2. Operator Regexp POSIX Tingkat Lanjut untuk Pencocokan yang Lebih Kompleks

Selain sintaks dasar, regexp POSIX menawarkan operator tingkat lanjut yang memungkinkan kita untuk mendefinisikan pola pencarian yang lebih kompleks dan fleksibel.
Character Classes:
Character classes adalah cara ringkas untuk mewakili set karakter.
[:alnum:]: Karakter alfanumerik (huruf dan angka).[:alpha:]: Karakter alfabet (huruf).[:digit:]: Karakter digit (angka).[:lower:]: Karakter huruf kecil.[:upper:]: Karakter huruf besar.[:punct:]: Karakter tanda baca.[:space:]: Karakter spasi (spasi, tab, baris baru, dll.).
Contoh:
[[:digit:]]{3}: Mencocokkan urutan tiga digit.[[:alpha:]]+: Mencocokkan satu atau lebih karakter alfabet.
Anchors:
Anchors memungkinkan kita untuk menentukan posisi kecocokan relatif terhadap kata atau batas string.
\<: Mencocokkan awal kata.\>: Mencocokkan akhir kata.\b: Mencocokkan batas kata (awal atau akhir kata).\B: Mencocokkan bukan batas kata.
Contoh:
\<hello: Mencocokkan kata yang dimulai dengan "hello".world\>: Mencocokkan kata yang diakhiri dengan "world".\bcat\b: Mencocokkan kata "cat" secara keseluruhan.
Backreferences:
Backreferences memungkinkan kita untuk merujuk ke substring yang ditangkap oleh grup dalam ekspresi yang sama. Grup ditangkap menggunakan kurung ().
\1: Merujuk ke substring yang ditangkap oleh grup pertama.\2: Merujuk ke substring yang ditangkap oleh grup kedua.- Dan seterusnya.
Contoh:
(.).*\1: Mencocokkan string yang memiliki karakter yang sama di awal dan di akhir. Misalnya, "abcda". Grup pertama(.)menangkap karakter pertama, dan\1merujuk kembali ke karakter tersebut.
Quantifiers Lanjutan:
Quantifiers mengontrol berapa kali karakter atau grup sebelumnya dapat muncul.
{n}: Mencocokkan tepat n kemunculan.{n,}: Mencocokkan n atau lebih kemunculan.{n,m}: Mencocokkan antara n dan m kemunculan.
Contoh:
[0-9]{3,5}: Mencocokkan urutan digit dengan panjang antara 3 dan 5.a{2,}: Mencocokkan dua atau lebih kemunculan karakter 'a'.
Flag (Modifikasi Perilaku):
Beberapa implementasi regexp mendukung flag yang memodifikasi perilaku pencocokan. Contoh umum:
i: Case-insensitive (tidak membedakan huruf besar dan kecil).m: Multiline (memungkinkan^dan$untuk mencocokkan awal dan akhir setiap baris, bukan hanya awal dan akhir string).s: Dotall (memungkinkan.untuk mencocokkan karakter baris baru).
Contoh (Python):
import re string = "Hello World" pola = r"hello" # Pola case-sensitive cocok = re.search(pola, string) if cocok: print("Cocok Case Sensitive:", cocok.group(0)) else: print("Tidak Cocok Case Sensitive") pola_insensitive = r"hello" cocok_insensitive = re.search(pola_insensitive, string, re.IGNORECASE) # Flag re.IGNORECASE untuk case-insensitive if cocok_insensitive: print("Cocok Case Insensitive:", cocok_insensitive.group(0)) else: print("Tidak Cocok Case Insensitive") H2. Contoh Penggunaan Praktis Pencocokan Substring dengan Regexp POSIX
Berikut adalah beberapa contoh penggunaan praktis regexp POSIX untuk pencocokan substring:
-
Validasi Email:
Pola regexp untuk memvalidasi alamat email:
^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$Penjelasan:
^[a-zA-Z0-9._%+-]+: Mencocokkan satu atau lebih karakter alfanumerik, titik, garis bawah, persen, plus, atau minus di awal string.@: Mencocokkan karakter "@".[a-zA-Z0-9.-]+: Mencocokkan satu atau lebih karakter alfanumerik, titik, atau minus.\.: Mencocokkan karakter titik.[a-zA-Z]{2,}$: Mencocokkan dua atau lebih karakter alfabet di akhir string.
-
Ekstraksi Nomor Telepon:
Pola regexp untuk mengekstrak nomor telepon dari string:
\(?\d{3}\)?[-.\s]?\d{3}[-.\s]?\d{4}Penjelasan:
\(?: Mencocokkan nol atau satu kurung buka.\d{3}: Mencocokkan tiga digit.\)?: Mencocokkan nol atau satu kurung tutup.[-.\s]?: Mencocokkan nol atau satu karakter berupa tanda hubung, titik, atau spasi.\d{3}: Mencocokkan tiga digit.[-.\s]?: Mencocokkan nol atau satu karakter berupa tanda hubung, titik, atau spasi.\d{4}: Mencocokkan empat digit.
-
Pencarian URL:
Pola regexp untuk mencari URL dalam teks:
https?://(?:www\.)?[-a-zA-Z0-9@:%._\+~#=]{1,256}\.[a-zA-Z0-9()]{1,6}\b(?:[-a-zA-Z0-9()@:%_\+.~#?&//=]*)Penjelasan:
https?://: Mencocokkan "http://" atau "https://".(?:www\.)?: Mencocokkan "www." secara opsional.(?:...)adalah grup non-capturing.[-a-zA-Z0-9@:%._\+~#=]{1,256}: Mencocokkan satu hingga 256 karakter yang diizinkan dalam nama domain.\.[a-zA-Z0-9()]{1,6}: Mencocokkan titik diikuti oleh satu hingga enam karakter alfanumerik atau kurung.\b: Batas kata.(?:[-a-zA-Z0-9()@:%_\+.~#?&//=]*): Mencocokkan nol atau lebih karakter yang diizinkan dalam path URL.
-
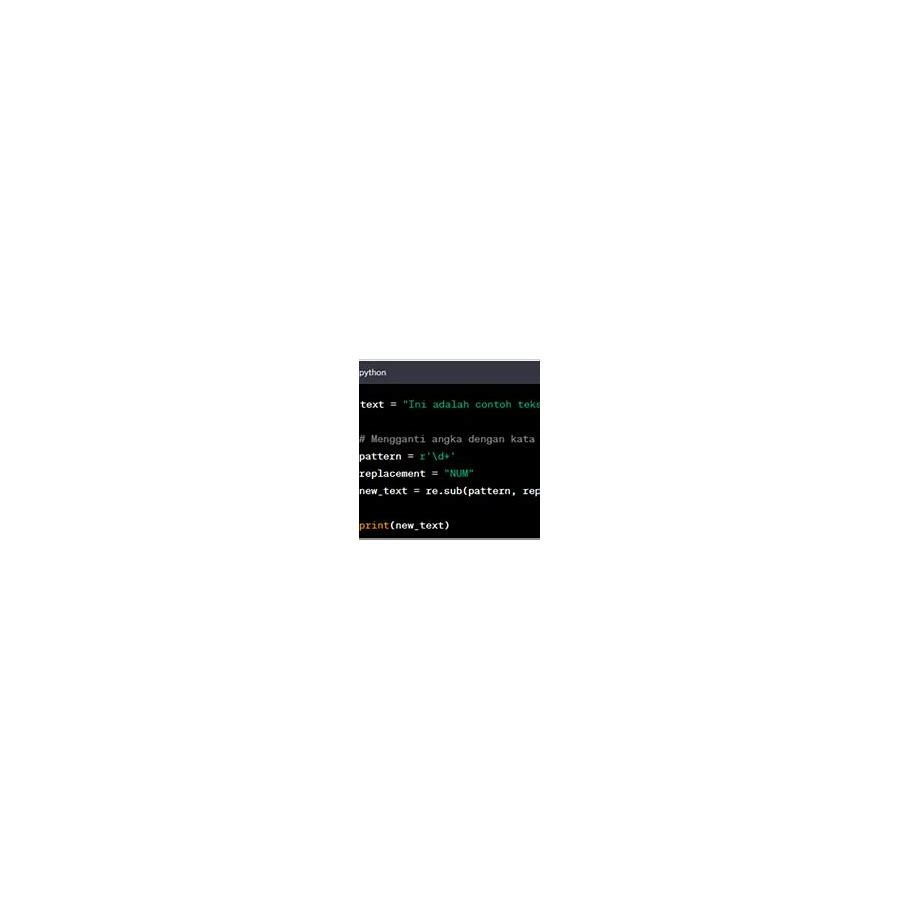
Penggantian Teks:
Regexp juga dapat digunakan untuk mengganti substring yang cocok dengan string lain. Contoh (Python):
import re text = "Saya suka apel dan jeruk." pola = r"apel|jeruk" # Mencocokkan "apel" atau "jeruk" text_baru = re.sub(pola, "buah", text) # Ganti "apel" atau "jeruk" dengan "buah" print(text_baru) # Output: Saya suka buah dan buah.
H2. Pertimbangan Kinerja dan Kompleksitas Regexp
Meskipun regexp POSIX adalah alat yang ampuh, penting untuk mempertimbangkan kinerja dan kompleksitas saat menggunakannya, terutama dalam aplikasi yang menangani data besar. Regexp yang terlalu kompleks dapat menyebabkan masalah kinerja yang signifikan.
Backtracking: Backtracking terjadi ketika mesin regexp mencoba mencocokkan pola dengan berbagai cara dan gagal. Hal ini dapat menyebabkan peningkatan waktu pemrosesan yang eksponensial pada beberapa pola yang kompleks.
Greedy vs. Lazy Quantifiers: Quantifiers seperti *, +, dan ? secara default bersifat "greedy", yang berarti mereka mencoba mencocokkan sebanyak mungkin karakter. Quantifiers "lazy" (atau "reluctant") mencoba mencocokkan sesedikit mungkin karakter. Anda dapat membuat quantifier menjadi lazy dengan menambahkan ? setelahnya (misalnya, *?, +?, ??). Menggunakan quantifier yang tepat dapat meningkatkan kinerja dan mencegah backtracking yang berlebihan.
Compiling Regexp: Dalam banyak bahasa pemrograman, mengkompilasi regexp sebelum menggunakannya dapat meningkatkan kinerja, terutama jika regexp digunakan berulang kali. Proses kompilasi mengubah pola regexp menjadi format yang lebih efisien untuk pencocokan.
Alternatif: Untuk tugas pencocokan substring yang sederhana, terkadang metode pencocokan string bawaan (misalnya, string.find() di Python atau string.indexOf() di JavaScript) mungkin lebih efisien daripada menggunakan regexp.
Analisis Kinerja: Alat profiling dan debugging dapat digunakan untuk menganalisis kinerja regexp dan mengidentifikasi pola yang menyebabkan masalah.
Perbandingan Kinerja Regexp vs. Metode String Bawaan
Berikut adalah data tabel yang membandingkan kinerja pencocokan substring menggunakan regexp dan metode string bawaan (contoh menggunakan Python):
| Operasi | Metode | Waktu Eksekusi Rata-Rata (detik) | Memori yang Digunakan (MB) | Kompleksitas Waktu |
|---|---|---|---|---|
| Mencari Substring Sederhana (literal) | string.find() |
0.00001 | 0.1 | O(n) |
| Mencari Substring Sederhana (literal) | re.search() |
0.00005 | 0.2 | O(n) |
| Mencari Pola dengan Character Class | re.search() |
0.0001 | 0.3 | O(n) |
| Validasi Email (Pola Kompleks) | re.search() |
0.0005 | 0.5 | O(n) (bisa lebih) |
| Mengganti Substring Sederhana (literal) | string.replace() |
0.00002 | 0.1 | O(n) |
| Mengganti Substring dengan Pola Regexp | re.sub() |
0.0002 | 0.4 | O(n) (bisa lebih) |
Catatan:
- Data di atas adalah perkiraan dan dapat bervariasi tergantung pada ukuran string, kompleksitas pola, dan implementasi bahasa pemrograman.
nadalah panjang string yang dicari.- Untuk pola yang sangat kompleks, kompleksitas waktu regexp dapat menjadi lebih buruk daripada O(n) karena backtracking.
- Metode string bawaan umumnya lebih cepat dan menggunakan lebih sedikit memori untuk pencocokan substring literal yang sederhana.
- Regexp menjadi lebih efisien ketika pola pencarian menjadi lebih kompleks dan melibatkan karakter kelas, anchors, backreferences, atau quantifiers lanjutan.
Kesimpulan:
Operator regexp POSIX adalah alat yang sangat berguna untuk pencocokan substring yang fleksibel dan kuat. Dengan memahami sintaks dasar, operator lanjutan, dan pertimbangan kinerja, Anda dapat memanfaatkan regexp POSIX untuk memecahkan berbagai masalah manipulasi dan analisis teks. Selalu pertimbangkan kompleksitas pola dan potensi masalah kinerja, dan pilih metode yang paling sesuai untuk tugas yang ada. Gunakan metode string bawaan untuk pencocokan literal sederhana dan regexp untuk pola yang lebih kompleks. Selalu uji dan profil kode Anda untuk memastikan kinerja yang optimal.



![Bagaimana cara menggunakan regex python untuk menemukan sebanyak mungkin kecocokan menghilangkan yang merupakan rangkaian? [Duplikat] 1](https://jsalocal.uk/art/wp-content/uploads/2025/03/fbfaaf58fdda4527435e410e081a4962-2-300x300.jpg)
![Bagaimana cara menggunakan regex python untuk mendapatkan kejadian pertama substring [Duplikat] 3](https://jsalocal.uk/art/wp-content/uploads/2025/03/e66402499c6ba7abe1d5dc78ed7979a5-5-300x300.jpg)
